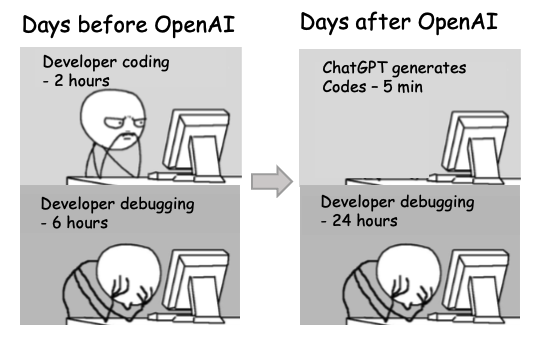
What can students learn from Generative AI chatbots like ChatGPT? What roles can chatbots play in collaborative engineering? Tutor? Facilitator? Pair programmer? Task master? Vibe coder? Coursework cheater? Or something else? Join us at 2pm GMT on Monday 1st December to discuss a position paper on this published at ITiCSE earlier this year. [1] From the abstract:
Collaboration is a crucial part of computing education. The increase in AI capabilities over the last couple of years is bound to profoundly affect all aspects of systems and software engineering, including collaboration. In this position paper, we consider a scenario where AI agents would be able to take on any role in collaborative processes in computing education. We outline these roles, the activities and group dynamics that software development currently include, and discuss if and in what way AI could facilitate these roles and activities. The goal of our work is to envision and critically examine potential futures. We present scenarios suggesting how AI can be integrated into existing collaborations. These are contrasted by design fictions that help demonstrate the new possibilities and challenges for computing education in the AI era.
We’ll be joined by one of the papers authors, Juho Leinonen, who’ll give us a lightning talk summary of the research. All welcome, meeting URL is public at zoom.us/j/96465296256 (meeting ID 9646-5296-256) but the password is private and pinned in the slack channel which you can join by following the instructions at sigcse.cs.manchester.ac.uk/join-us
(Cite this article using DOI:10.59350/c26zw-0tm88 provided by rogue-scholar.org)
References
- Natalie Kiesler, Jacqueline Smith, Juho Leinonen, Armando Fox, Stephen MacNeil, Petri Ihantola (2025) The Role of Generative AI in Software Student CollaborAItion, ITiCSE 2025: Proceedings of the 30th ACM Conference on Innovation and Technology in Computer Science Education, Pages 72 – 78, DOI:10.1145/3724363.3729040